
Introduction: Why Tokenization and Embeddings Matter in Modern AI
In the race to implement AI across the enterprise, many engineering leaders focus primarily on selecting and deploying large language models. However, the true differentiator in successful AI implementations often lies in a less discussed component: the embedding layer. Embeddings transform raw data—whether text, images, or specialized domain information—into the numerical representations that AI systems can actually process. As the interface between human-readable information and machine learning systems, embeddings fundamentally determine what your AI can "see" and understand.
As a CTO or engineering leader, understanding these concepts directly impacts how successfully you can implement AI solutions, the computational resources you'll need, and ultimately the capabilities your systems will possess. Whether you're building a customer support chatbot, implementing semantic search, or developing content generation tools, RAG systems mastering these fundamentals is essential for technical leadership in the AI era.
This guide will provide you with both the theoretical understanding and practical implementation knowledge needed to make strategic decisions about AI in your organization.
The Business Impact of Getting Tokenization and Embeddings Right
Before diving into the technical details, let's clarify why getting tokenization and embeddings right matters from a business perspective:
- Cost Efficiency: Proper tokenization directly impacts computational requirements. Inefficient tokenization can increase token count directly translating to higher inference costs when using commercial AI APIs.
- Quality of Results: The quality of embeddings affects virtually every downstream task in your AI systems. Better embeddings lead to more accurate search results, more relevant recommendations, and more natural language generation.
- System Architecture: Your choice of tokenization and embedding strategies influences your entire AI infrastructure, from storage requirements to processing pipelines.
- Model Performance: Research shows that tokenization alone can impact model performance, while embedding quality can make or break specialized applications.
Organizations that master these fundamentals gain a significant competitive edge in capturing this value.
Understanding the Core Concepts
Tokenization: Breaking Text into Meaningful Units
Tokenization is the first step in text processing for AI systems—the process of breaking text into discrete units (tokens) that can be processed by a machine learning model.
Types of Tokenization
- Word-based tokenization: Splits text at word boundaries
1 # Simple word tokenization
2 text = "The quick brown fox jumps over the lazy dog."
3 tokens = text.split()
4 # Result: ['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog.']
52. Character-based tokenization: Treats each character as a token
1 # Character tokenization
2 chars = list(text)
3 # Result: ['T', 'h', 'e', ' ', 'q', 'u', 'i', 'c', 'k', ...]
43. Subword tokenization: The gold standard for modern NLP, breaking words into meaningful subunits
1 # Using a subword tokenizer like BPE (example with 🤗 Transformers)
2 from transformers import AutoTokenizer
3
4 tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
5 tokens = tokenizer.tokenize("The tokenization of unconventional words demonstrates subword units.")
6 # Result: ['The', 'token', '##ization', 'of', 'unconventional', 'words', 'demonstrates', 'sub', '##word', 'units', '.']
7Subword tokenization algorithms like Byte-Pair Encoding (BPE), WordPiece, and SentencePiece balance vocabulary size with semantic richness, allowing models to recognize common word parts while handling rare words effectively.
Common Tokenization Pitfalls
- Vocabulary Limitations: Restricting vocabulary size too much forces excessive splitting of words, while too large a vocabulary leads to inefficient models.
- Language Bias: Most tokenizers are trained primarily on English, causing them to tokenize other languages inefficiently. For instance, Chinese characters might each become individual tokens, while entire English words remain single tokens.
- Special Character Handling: Many systems struggle with handling emojis, technical symbols, or domain-specific notations, sometimes breaking them into meaningless subunits.
- Contextual Boundaries: Tokenizers don't inherently understand semantic boundaries, potentially splitting meaningful phrases in ways that lose their coherence.
Embeddings: Converting Tokens to Vectors
Once text is tokenized, the next step is converting tokens into numerical representations that capture semantic meaning. These vector representations are called embeddings.
Types of Embeddings
- Static Embeddings: Fixed vector representations for words
- Word2Vec
- GloVe
- FastText
- Contextual Embeddings: Dynamic representations that change based on surrounding context
- OpenAI text-embedding-3
- BERT embeddings
- GPT embeddings
- T5 embeddings
Visualization: From Words to Vectors
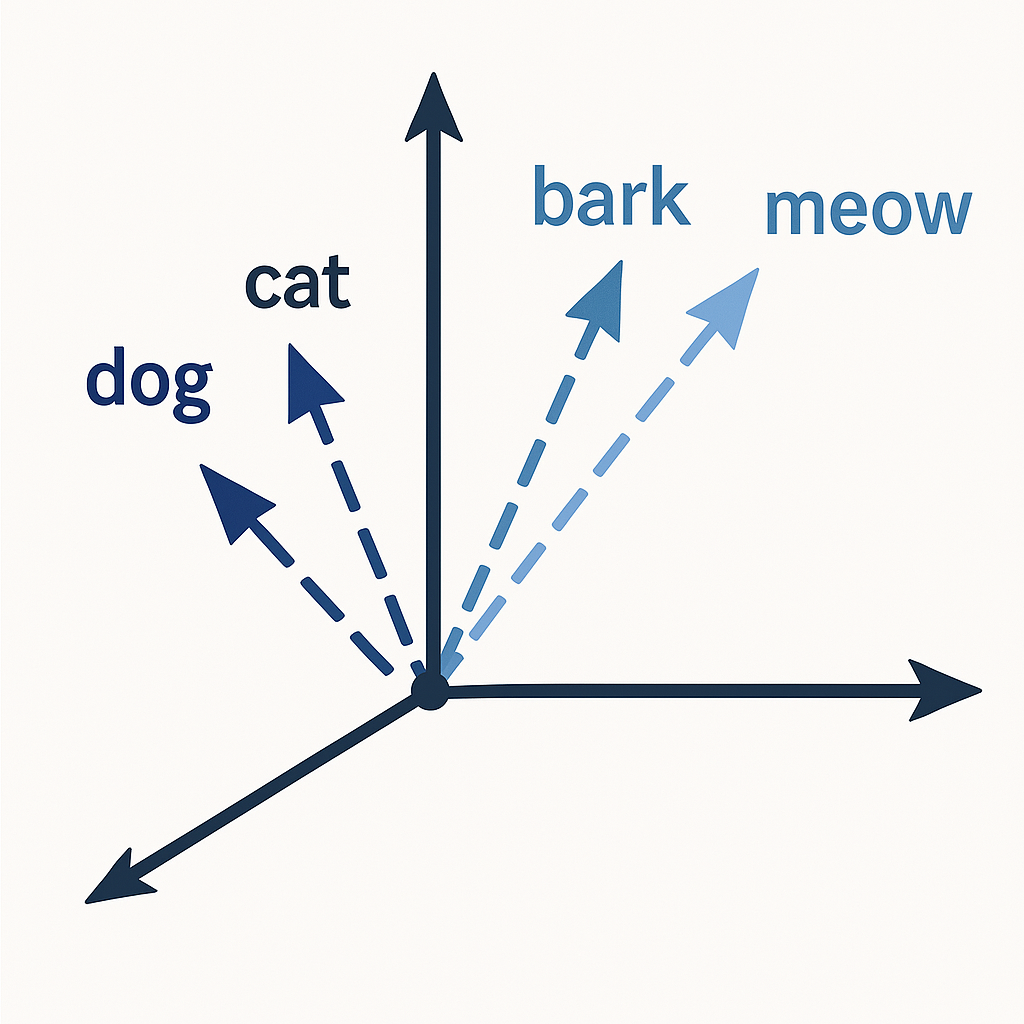
Code Example: Generating Embeddings
1# Using sentence-transformers to generate embeddings
2from sentence_transformers import SentenceTransformer
3
4# Load a pre-trained model
5model = SentenceTransformer('all-MiniLM-L6-v2')
6
7# Generate embeddings for sentences
8sentences = [
9 "This is an example sentence",
10 "Each sentence is converted to a vector"
11]
12
13embeddings = model.encode(sentences)
14print(f"Embedding shape: {embeddings.shape}")
15# Result: Embedding shape: (2, 384)
16The Transformer Connection: How It All Fits Together
Transformers have revolutionized NLP largely due to their ability to process tokens and their embeddings in a highly parallelized, context-aware manner.
Clarifying Common Misconceptions
Before diving deeper, let's address some common questions and misconceptions:
Are Embeddings Transformers?
No, embeddings and transformers are distinct concepts:
- Embeddings are vector representations of tokens or words, essentially mapping discrete symbols to continuous vector spaces.
- Transformers are neural network architectures that _use_ embeddings as inputs, but then process them through attention mechanisms and feed-forward networks.
Think of embeddings as the data representation, while transformers are the processing machinery. The embedding layer is typically just the first component of a transformer model, converting input tokens into vectors that the rest of the architecture can process.
Does Vectorization Happen Before Embedding?
This question reveals a common terminology confusion:
- Tokenization comes first - converting raw text into tokens
- Embedding is the vectorization process - converting tokens into vectors
The term "vectorization" is sometimes used to describe the entire process from raw text to vectors, but in the technical pipeline, embedding _is_ the vectorization step. There is no separate vectorization before embedding in standard NLP pipelines.
1# The complete pipeline:
2text = "Hello world"
3tokens = tokenizer.tokenize(text) # ['Hello', 'world']
4token_ids = tokenizer.convert_tokens_to_ids(tokens) # [8667, 1362]
5embedding_vectors = embedding_layer(token_ids) # The actual vectorization
6The Transformer Architecture
A transformer model processes embeddings through several key components:
- Input Embeddings: Convert tokens to vectors
- Positional Encodings: Add information about token position
- Self-Attention Mechanism: Allow the model to focus on relevant parts of the input
- Feed-Forward Networks: Process the contextualized embeddings
- Output Layer: Generate predictions based on the processed embeddings
How Transformers Use Embeddings
In a transformer model, embeddings serve multiple crucial roles:
- Initial Representation: Token embeddings provide the initial representation of input text
- Attention Computation: The quality of embeddings directly impacts how effectively the attention mechanism can identify relevant relationships
- Contextual Understanding: Through multiple layers of processing, embeddings become increasingly context-aware
- Output Generation: Final predictions or generations are based on the transformed embeddings
Technical Implementation Considerations
When implementing transformer-based systems, several embedding-related factors demand attention:
- Embedding Dimension: Higher dimensions capture more information but require more computation
- Training Strategy: Whether to fine-tune pre-trained embeddings or train from scratch
- Storage Requirements: Embedding tables can be very large (billions of parameters)
- Quantization Options: Precision reduction to save space and computation
Implementation Framework for Engineering Leaders
As an engineering leader implementing AI systems leveraging these technologies, follow this framework for success:
1. Assess Your Requirements
| Requirement | Tokenization Consideration | Embedding Consideration |
|---|---|---|
| Multilingual Support | Choose tokenizers trained on many languages | Use multilingual embedding models |
| Domain Specificity | Consider custom vocabulary augmentation | Domain adaptation of embeddings |
| Computational Constraints | Optimize vocabulary size | Consider dimensionality reduction |
Domain Knowledge in Embedding Models
A critical question for engineering leaders is: Where does domain knowledge come from in embedding models, and how can we incorporate it?
Sources of Domain Knowledge
- Pre-training Data: The primary source of knowledge in embeddings comes from their pre-training data. Models like BERT and GPT are trained on vast corpora spanning books, websites, and academic papers.
- Fine-tuning: Domain-specific knowledge can be injected through fine-tuning on specialized datasets:
1 # Fine-tuning a sentence transformer on domain-specific data
2 from sentence_transformers import SentenceTransformer, losses, InputExample
3 from torch.utils.data import DataLoader
4
5 # Load pre-trained model
6 model = SentenceTransformer('all-MiniLM-L6-v2')
7
8 # Prepare domain-specific training data
9 train_examples = [
10 InputExample(texts=['query1', 'relevant_doc1'], label=1.0),
11 InputExample(texts=['query2', 'relevant_doc2'], label=0.8),
12 InputExample(texts=['query3', 'irrelevant_doc'], label=0.0)
13 ]
14
15 train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
16
17 # Train with cosine similarity loss
18 train_loss = losses.CosineSimilarityLoss(model)
19
20 # Train the model
21 model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10)
22- Knowledge Graphs Integration: For highly specialized domains, knowledge graphs can be integrated with embeddings:
- Entity Linking: Map text references to knowledge graph entities
- Graph-enhanced Embeddings: Incorporate graph structure into embedding space
- Hybrid Retrieval: Combine embedding similarity with graph traversal
- Domain-specific Corpora: Training tokenizers and embeddings from scratch on domain-specific text:
1 # Step 1: Train a custom BPE tokenizer on domain-specific text
2 from tokenizers import Tokenizer, models, pre_tokenizers, trainers
3
4 # Initialize a BPE tokenizer
5 tokenizer = Tokenizer(models.BPE())
6 tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=True)
7
8 # Define trainer with domain-specific vocabulary size
9 trainer = trainers.BpeTrainer(
10 vocab_size=5000,
11 special_tokens=["<s>", "</s>", "<unk>", "<pad>", "<mask>"]
12 )
13
14 # Train on domain corpus
15 domain_files = ["path/to/domain_texts.txt"] # Your domain-specific corpus
16 tokenizer.train(files=domain_files, trainer=trainer)
17
18 # Save the tokenizer
19 tokenizer.save("domain_tokenizer.json")
20
21 # Step 2: Use the tokenizer with a transformer for domain embeddings
22 from transformers import AutoModel, AutoTokenizer, AutoConfig
23 from transformers import DataCollatorWithPadding, Trainer, TrainingArguments
24 import torch
25
26 # Load your custom tokenizer
27 domain_tokenizer = AutoTokenizer.from_pretrained("domain_tokenizer.json")
28
29 # Initialize model (e.g., small BERT) that will be trained from scratch
30 config = AutoConfig.from_pretrained(
31 "bert-base-uncased",
32 vocab_size=len(domain_tokenizer),
33 hidden_size=256,
34 num_hidden_layers=6,
35 num_attention_heads=8
36 )
37
38 model = AutoModel.from_config(config)
39
40 # Train your model with domain data
41 # (This is simplified - would need dataset preparation)
42 training_args = TrainingArguments(
43 output_dir="./domain-embedding-model",
44 per_device_train_batch_size=32,
45 learning_rate=5e-5,
46 num_train_epochs=3
47 )
48
49 # The resulting model can generate domain-optimized embeddings
50When to Use Custom Domain Knowledge
| Organization Type | Domain Complexity | Recommended Approach |
|---|---|---|
| Startups/SMBs | Low-Medium | Fine-tune existing embeddings |
| Enterprise | Medium-High | Hybrid approach with KG augmentation |
| Specialized Industry | Very High | Custom embeddings + industry ontologies |
The investment in domain-specific knowledge integration should be proportional to how specialized your domain is and how much general embeddings fail to capture critical nuances.
2. Choose Your Approach
For Small to Medium Organizations:
- Recommendation: Focus on speed-to-value by applying pre-trained models directly to your data rather than building custom solutions
- Implementation Path:1. Use Hugging Face's transformers library for access to pre-trained models2. Fine-tune on domain-specific data if necessary3. Deploy using managed inference services
Key Callout: Focus on your metrics and evaluations first. Understanding how pre-trained models perform on *your specific data* will yield more immediate value than model customization. Spend time defining what success looks like for your use case before investing in model improvements.
1# Example: Loading pre-trained model and tokenizer
2from transformers import AutoModel, AutoTokenizer
3import torch
4
5model_name = "sentence-transformers/all-MiniLM-L6-v2"
6tokenizer = AutoTokenizer.from_pretrained(model_name)
7model = AutoModel.from_pretrained(model_name)
8
9# Process a batch of text
10inputs = tokenizer(["Hello world", "How are you?"], padding=True, return_tensors="pt")
11outputs = model(**inputs)
12
13# Extract sentence embeddings (mean pooling)
14# Get attention mask to ignore padding tokens
15attention_mask = inputs['attention_mask']
16
17# Mean pooling - take attention mask into account for correct averaging
18input_mask_expanded = attention_mask.unsqueeze(-1).expand(outputs.last_hidden_state.size()).float()
19embeddings = torch.sum(outputs.last_hidden_state * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
20For Large Organizations with Specialized Needs:
- Recommendation: Consider custom tokenization and embedding approaches
- Implementation Path:1. Collect domain-specific corpus2. Train custom tokenizer (e.g., using 🤗 Tokenizers library)3. Pre-train embeddings on domain data4. Integrate with existing transformer architectures
Key Callout: Let your data and metrics guide investment decisions. Measure how pre-trained models perform on your specialized content first. Only pursue custom tokenization when you have clear evidence of terminology gaps or when domain-specific language significantly impacts performance metrics.
1# Training a custom tokenizer with Hugging Face tokenizers
2from tokenizers import Tokenizer, models, pre_tokenizers, trainers
3from tokenizers.processors import TemplateProcessing
4
5# Initialize a BPE tokenizer
6tokenizer = Tokenizer(models.BPE())
7
8# Set up pre-tokenization and training
9tokenizer.pre_tokenizer = pre_tokenizers.Whitespace()
10
11# Train on your corpus
12trainer = trainers.BpeTrainer(vocab_size=30000, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
13files = ["path/to/corpus.txt"] # Your domain-specific text
14tokenizer.train(files, trainer)
15
16# Save the tokenizer
17tokenizer.save("path/to/tokenizer.json")
183. Optimize for Production
- Embedding Storage: Consider approximate nearest neighbors (ANN) for efficient similarity search
- Batch Processing: Optimize batch sizes for tokenization and embedding generation
- Caching Strategy: Cache embeddings for frequently accessed content
- Monitoring: Track token usage and embedding quality metrics
Measuring Success: Key Metrics for Tokenization and Embeddings
Track these metrics to ensure your implementation is effective:
- Average Tokens per Character: Monitor tokenization efficiency across languages
- Token Utilization Distribution: Ensure vocabulary is well-utilized
- Embedding Cluster Quality: Measure how well similar concepts cluster in embedding space
- Task-Specific Performance: Ultimately, measure improvements in downstream tasks
Embedding Alignment and Vector Store Considerations
A common architectural question arises when organizations build AI systems: Does it matter if different embedding models are used across your system?
The answer is nuanced and has significant implications for system design:
Embedding Alignment Matters
When embeddings from different models are used in the same pipeline (e.g., one for vector store retrieval and another within an LLM), several issues can arise:
- Semantic Drift: Different embedding spaces may encode semantics differently, causing retrieval mismatches
- Dimensionality Mismatch: Models may produce vectors of different dimensions
- Contextual vs. Static Embeddings: Some models produce contextual embeddings, while others might create static embeddings
Best Practices for Mixed-Embedding Systems
If your architecture requires using different embedding models:
- Alignment Training: Consider training alignment layers between embedding spaces
- Consistent Preprocessing: Use identical tokenization and preprocessing steps
- Benchmark Retrieval Quality: Test cross-model retrieval accuracy on a validation set
- Hybrid Retrieval: When possible, use multiple retrieval mechanisms to compensate for misalignment
1# Example: Evaluating embedding alignment between two models
2from sentence_transformers import SentenceTransformer
3import numpy as np
4from sklearn.metrics.pairwise import cosine_similarity
5
6# Load two different embedding models
7retrieval_model = SentenceTransformer('all-MiniLM-L6-v2')
8llm_embedding_model = SentenceTransformer('all-mpnet-base-v2')
9
10# Test set
11test_sentences = ["This is a test sentence", "This is a similar sentence", "This is completely different"]
12
13# Generate embeddings from both models
14retrieval_embeddings = retrieval_model.encode(test_sentences)
15llm_embeddings = llm_embedding_model.encode(test_sentences)
16
17# Calculate similarity matrices for both
18sim_retrieval = cosine_similarity(retrieval_embeddings)
19sim_llm = cosine_similarity(llm_embeddings)
20
21# Compare similarity structures
22alignment_score = np.corrcoef(sim_retrieval.flatten(), sim_llm.flatten())[0, 1]
23print(f"Embedding alignment score: {alignment_score}")
24When to Use the Same Embedding Model
For maximum coherence, using the same embedding model throughout your pipeline is ideal, especially when:
- The LLM and retrieval system are tightly coupled
- Precision in retrieval is critical to application success
- The domain is highly specialized
However, practical constraints like cost, latency, and resource availability often require compromises. The key is to measure and mitigate any misalignment through careful testing and calibration.

Emerging Trends and Future Developments
Stay ahead of the curve by monitoring these developments:
- Tokenization Innovations:
- Learned tokenization that adapts to specific domains
- Hybrid approaches combining different tokenization strategies
- Embedding Advances:
- Multimodal embeddings unifying text, image, and audio
- Sparse embeddings enabling more efficient retrieval
- Adaptive-dimensionality embeddings are emerging, aiming to reduce model size without sacrificing performance (experimental).
- Architectural Evolution:
- More efficient attention mechanisms reducing embedding processing costs
- Parameter-efficient fine-tuning techniques
Implementation Roadmap: Next Steps for Engineering Leaders
- Audit Current Systems:
- Evaluate existing tokenization efficiency
- Benchmark embedding quality on your specific use cases
- Establish a Proof of Concept:
- Implement a small-scale test of improved tokenization and embeddings
- Measure performance gains against current systems
- Plan for Scale:
- Design embedding storage and retrieval architecture
- Establish embedding update and retraining pipelines
- Develop Expertise:
- Train engineering team on these fundamental concepts
- Consider specialized roles for NLP infrastructure
Conclusion: The Strategic Advantage of Mastering the Fundamentals
As AI continues to transform business operations, engineering leaders who understand the underlying mechanics of tokenization and embeddings will make better strategic decisions about AI implementation. By mastering these fundamental concepts, you'll be better positioned to:
- Make informed build-vs-buy decisions for AI capabilities
- Accurately estimate computational and storage requirements
- Identify opportunities for competitive differentiation through custom AI solutions
- Communicate effectively with both technical teams and business stakeholders
The organizations that excel in the AI era will be those that not only implement the latest models but deeply understand how to optimize them for their specific needs. Tokenization and embeddings are the foundation upon which that optimization must be built.
Looking for expert guidance on implementing these concepts in your organization? Our team specializes in helping engineering leaders build robust, efficient AI systems tailored to their specific business needs. Contact us for a consultation on optimizing your AI implementation.